
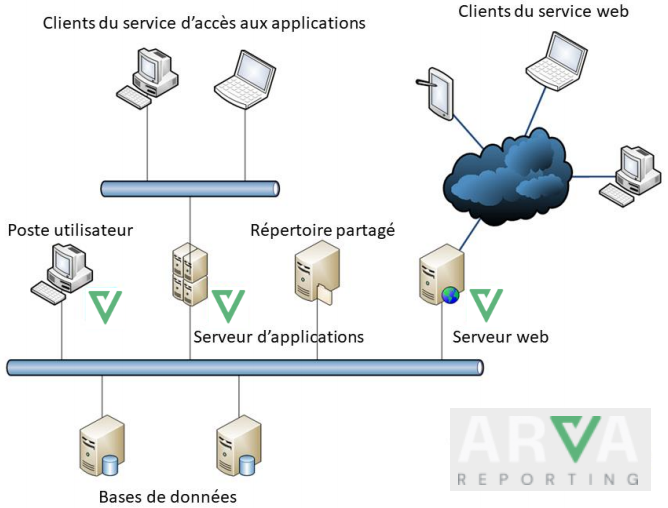
Intégration de VIGILENS dans l’architecture de l’entreprise
Poste utilisateur
Les applications Arva Reporting peuvent être installées directement sur un poste individuel. Ce sont des applications Windows 32 bits permettant la création, l’exécution de requêtes et leur restitution sous différents formats.
Arva Reporting est développé en langage C++ en respect des règles et outils Microsoft (MFC), assurant ainsi la compatibilité avec les environnements Windows.
Elles utilisent ODBC pour accéder aux bases de données.
Il est également préconisé de créer un compte dédié à Arva Reporting pour l’accès aux bases de données, ceci permettant une meilleure identification au niveau de la base des actions menées par le biais du logiciel.
Les requêtes propres à un utilisateur (non publiées et associées à un compte Arva Reporting donné) sont stockées dans un répertoire défini dans l’application d’administration de Arva Reporting (nommée AdminTool). Nous préconisons une sauvegarde régulière de ces répertoires utilisateurs.
Avant la version 6 du logiciel, ce poste utilisateur doit disposer d’un fichier de licence machine dans le même répertoire que l’exécutable Arva Reporting pour pouvoir être opérationnel.

Répertoire partagé
Ce répertoire regroupe l’ensemble des données nécessaires aux utilisateurs :
- définition des comptes utilisateurs Arva Reporting (utilisateurs, groupes, sécurités)
- paramétrage des accès aux bases de données
- paramétrage spécifique aux bases JD Edwards
- requêtes publiées (requêtes partagées et mises disposition de tous les utilisateurs)
- définitions partagées (fonctions, jointures, gestion des décimales des devises)
- …
Voir la procédure d’installation pour plus de détails sur les noms de répertoire et de fichiers de paramétrage ou de travail.
Ce répertoire partagé doit disposer d’un fichier de licence globale, commun à l’ensemble de l’architecture, pour que cette dernière soit opérationnelle.
Ce répertoire partagé doit disposer d’un fichier de licence globale, commun à l’ensemble de l’architecture, pour que cette dernière soit opérationnelle.

Nous préconisons une sauvegarde régulière de ce répertoire partagé.
Si le concepteur de la requête n’a pas précisé un fichier existant cible, chaque restitution de type fichier entraîne la création d’un nouveau fichier dans le répertoire correspondant à la requête (à partir du répertoire « CS » de l’arborescence).
Ceci peut induire une augmentation significative du volume de données dans le sous-répertoire CS. Il peut s’avérer utile d’effectuer régulièrement des purges des fichiers de restitution (fichiers textes, Excel et PDF).
Serveur d’application
L’installation de ce composant optionnel est recommandé.
Arva Reporting peut également être exécuté, en création et exécution de requêtes, depuis un serveur d’accès aux applications (Windows TSE, Citrix, …). Tout en étant facultative, cette architecture permet de gagner en souplesse par rapport à de multiples installations monopostes :
- cohérence de la configuration
- montée de version facilitée
- …
Ce serveur (ou groupe de serveurs) peut se substituer ou compléter les postes utilisateurs décrits précédemment.
Les caractéristiques exposées pour le poste utilisateur s’appliquent au serveur.
Les postes clients de ce serveur accèdent à l’application par son intermédiaire et ne nécessitent donc aucun élément propre à Arva Reporting .
Serveur Web
L’installation de ce composant optionnel est recommandé.
Arva Reporting peut également être exécuté, en exécution de requêtes uniquement, depuis un serveur web. Ceci est bien entendu facultatif mais permet de bénéficier d’une expérience utilisateur optimale, l’exécution des requêtes au travers de Arva Reporting Web apportant des fonctionnalités plus étendues qu’au travers de sa version application Windows.
Ce serveur complète les postes utilisateurs ou serveurs d’application décrits précédemment, qui restent nécessaires pour la création des requêtes.
Ce serveur web doit disposer de :
- Une installation de Arva Reporting dont les caractéristiques sont exposées pour le poste utilisateur (y compris la licence machine)
- L’interface utilisateur Web proprement dite
- Une base de données PostgreSQL
L’interface utilisateur Web est développée avec Python, un interpréteur est embarqué dans le service Windows “Arva Reporting Web” afin d’être indépendant de ce qui pourrait être installé sur la machine.
Une base de données PostgreSQL est nécessaires pour enregistrer les données spécifiques de l’interface web (requêtes placées en favoris, pages d’accueils, indicateurs, …). Il faut au minimum une base de données PostgreSQL en version 10. Un package d’installation permet d’installer le moteur de base de donnée et de l’initialiser de la manière attendu par Arva Reporting. (Création d’une base nommé “vigilens” et d’un compte spécifique pour l’administrer)
Ces pages web font appel au service web qui intègre un serveur HTTP applicatif (CherryPy). Les pages sont stockées dans le répertoire d’installation de Arva Reporting .

Le serveur web peut générer une grande quantité de log. Ces logs ne sont pas effacés automatiquement, il est donc recommandés de faire le nettoyage régulièrement. Les fichiers sont par défaut placer dans le dossier d’installation de Arva Reporting, cependant il est possible de les placer ailleurs par le biais de l’application WebConfig.
Le serveur web nécessite l’utilisation d’un compte Windows pour l’authentification anonyme. Ce compte doit avoir les droits permettant l’exécution de Arva Reporting (par exemple : accès au répertoire partagé) et les accès en exécution à l’objet DCOM.
Les postes clients de ce serveur accèdent à l’application par son intermédiaire (navigateur web, requêtage http de MS Excel, tâche d’un menu JD Edwards EnterpriseOne, …) et ne nécessitent donc aucun élément propre à Arva Reporting.
Les versions de navigateur dont la compatibilité est couverte sont : Microsoft Internet Explorer 11, pour les autres navigateurs il est toujours recommandés d’utiliser les plus récents dès que possible.